we introduce SpatialReasoner, a novel large vision-language model (LVLM) that address 3D spatial reasoning with explicit 3D representations shared between stages -- 3D perception, computation, and reasoning. Explicit 3D representations provide a coherent interface that supports advanced 3D spatial reasoning and enable us to study the factual errors made by LVLMs.

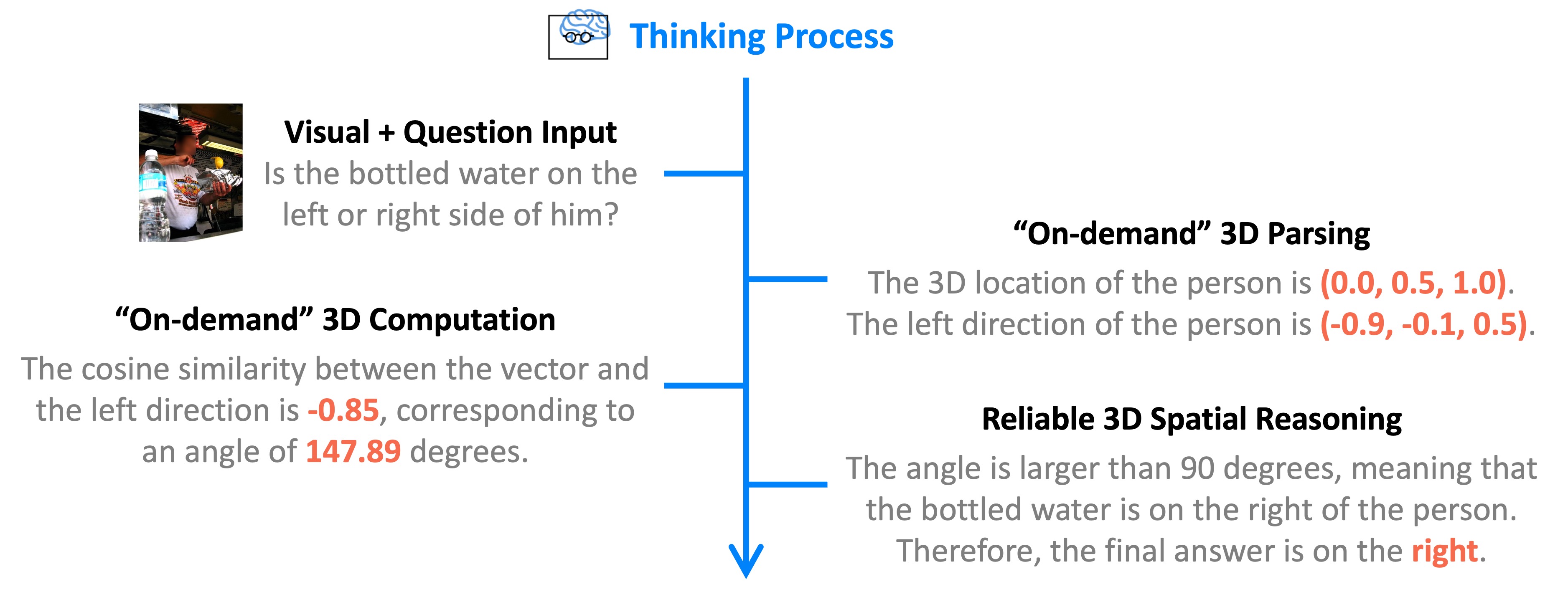
Key Design I: Explicit Spatial Reasoning
Key Design II: Generalizable Spatial Reasoning
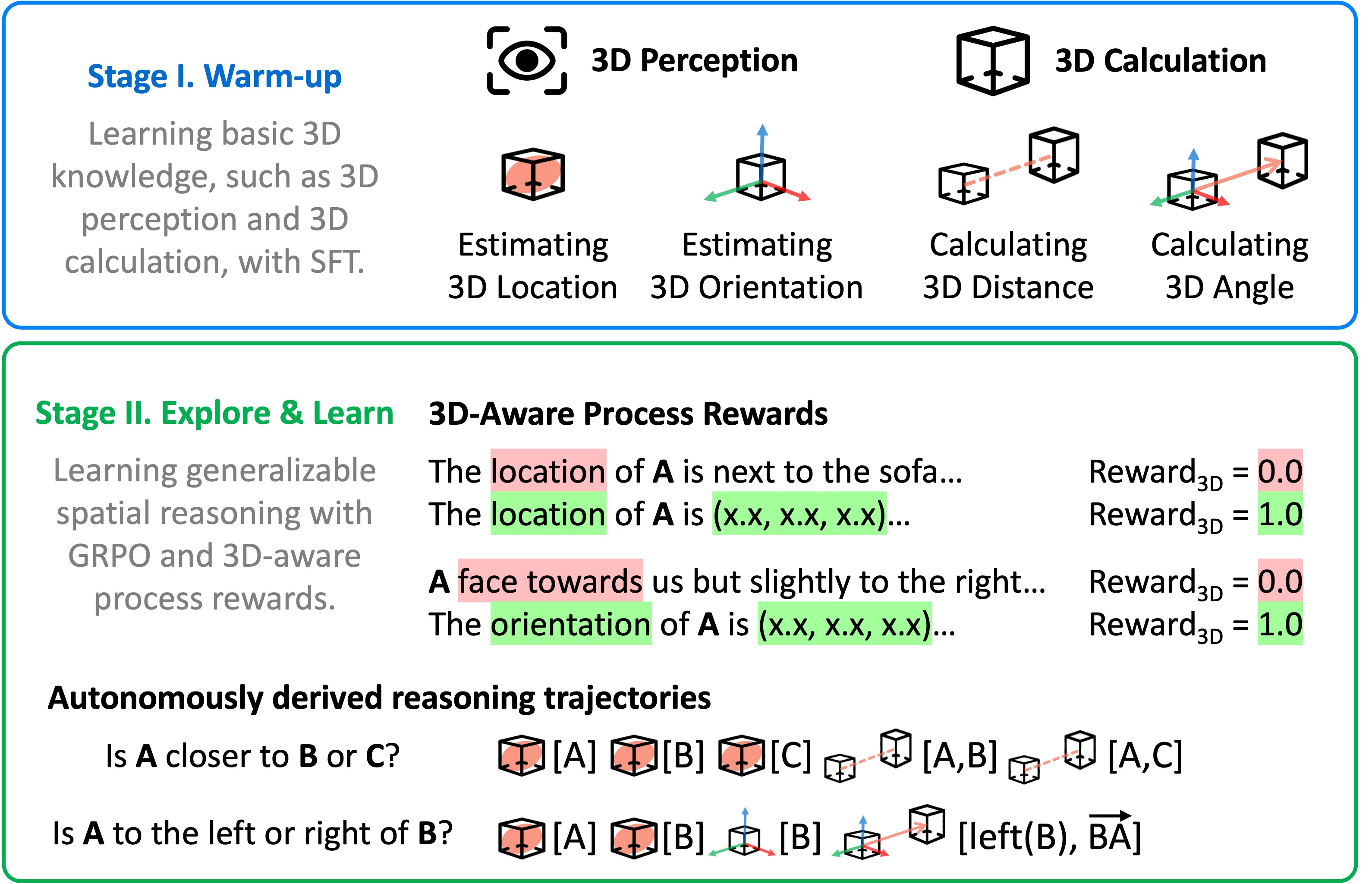
Key Findings
SpatialReasoner models. We experimented on a variety of SpatialReasoner models with different data and training methods.
- SpatialReasoner-SFT. Qwen2.5-VL directly finetuned with SFT on synthetic spatial reasoning VQA data, as widely adopted in prior works
. - SpatialReasoner-Zero. Qwen2.5-VL first warmed up with SFT on basic 3D knowledge, and then finetuned with GRPO using format, accuracy, and 3D-aware process rewards.
- SpatialReasoner. Qwen2.5-VL first warmed up with SFT on synthetic spatial reasoning VQA data, and then finetuned with GRPO using format and accuracy rewards.
Evaluation on 3DSRBench
| model | 3DSRBench | ||||
|---|---|---|---|---|---|
| Overall | Height | Location | Orientation | Multi-Object | |
| Open-sourced | |||||
| Qwen2.5-VL | 48.4 | 44.1 | 62.7 | 40.6 | 40.5 |
| SpatialLLM | 44.8 | 45.8 | 61.6 | 30.0 | 36.7 |
| SpatialRGPT | 32.7 | 55.9 | 39.0 | 27.8 | 20.0 |
| SpatialRGPT+Depth | 48.4 | 55.9 | 60.0 | 34.2 | 42.3 |
| Propietary | |||||
| GPT-4o | 44.2 | 53.2 | 59.6 | 21.6 | 39.0 |
| Gemini 2.0 | 51.1 | 53.0 | 67.1 | 35.8 | 43.6 |
| QwenVLMax | 52.0 | 45.1 | 70.7 | 37.7 | 44.8 |
| Ours | |||||
| SpatialReasoner-Zero | 54.0 | 46.4 | 67.3 | 48.4 | 47.2 |
| SpatialReasoner-SFT | 58.3 | 51.9 | 73.5 | 50.7 | 50.3 |
| SpatialReasoner | 60.3 | 52.5 | 75.2 | 55.2 | 51.8 |
Evaluation on 3DSRBench
| model | in-distribution | out-of-distribution | |||
|---|---|---|---|---|---|
| overall | height | location | orientation | multi-object | |
| reference | |||||
| Qwen2.5-VL | 48.4 | 44.1 | 62.7 | 40.6 | 40.5 |
| ours | |||||
| SpatialReasoner-Zero | 53.7 | 40.6 | 68.4 | 50.2 | 46.6 |
| SpatialReasoner-SFT | 52.2 | 44.9 | 69.5 | 48.9 | 40.0 |
| SpatialReasoner | 56.4 | 52.5 | 72.6 | 54.1 | 43.4 |
Qualitative Comparisons
Open Source
- Code for training SpatialReasoner models.
- Code for generating synthetic spatial reasoning VQA data.
- Huggingface collection for both training data (Basic3D, SFT, RL data) and pretrained SpatialReasoner-series models.
Miscellaneous
License. Our SpatialReasoner and SpatialReasonerDataGen is released under the Creative Commons Attribution 4.0 license. By accessing and using our SpatialReasoner and SpatialReasonerDataGen, you agree to follow the terms of access specified here.